Best Selling Products

Adobe Premiere Pro Account
99 USD

Upgrade Genuine Office 365
49 USD

Plugin Retouch4me
69 USD

Windows 10 & 11 Pro Key
36 USD

Upgrade Duolingo Super
29 USD

Capcut Pro 1 Year
39 USD

Copyright Adobe Lightroom Account
59 USD

Adobe Photoshop Copyright - Full App
120 USD

Autodesk All App Account Copyright
120 USD

Genuine Cheap Canva Pro
39 USD

Freepik Premium Account
59 USD

Upgrade genuine Capture One account
120 USD

ChatGPT Plus Account (GPT-4)
16 USD

MidJourney Account
29 USD

Genuine Adobe Illustrator account
99 USD
Top AI Models of 2026: An Analysis of Claude Opus 4.6, GPT-5.4, and Gemini 3.1 Pro
Nội dung
This article provides a detailed analysis of the competition between Claude Opus 4.6, GPT-5.4, and Gemini 3.1 Pro based on the latest benchmarks from April 2026. Beyond the numbers, the content dives into the strengths and weaknesses of each model in coding, reasoning, multitasking, and deployment costs.

1. The Big Picture: When There Is No Longer a “Dominant Leader”
AI rankings in April 2026 reveal a transformational shift: no single model is overwhelmingly superior. Claude Opus 4.6, Gemini 3.1 Pro, and GPT-5.4 all achieve exceptionally high performance levels, with score differences across many benchmarks ranging from only 1–3%. This indicates that the competition has entered a stage of “basic quality saturation” and is now focused on depth of capability.
However, this balance does not mean the models have become similar. On the contrary, each model is evolving in a distinct direction. Anthropic focuses on safety, consistency, and controlled reasoning, enabling its model to provide logical responses with fewer errors. OpenAI’s GPT-5.4 follows a general-purpose strategy, optimizing performance across a wide variety of tasks within a single ecosystem. Meanwhile, Google DeepMind emphasizes broad reasoning capabilities and cost-efficient performance, allowing Gemini to excel in complex problem-solving.
The most significant change lies in how users approach AI. In the past, the goal was to select the “best model.” Today, the priority is selecting the “most suitable model.” A model may not rank first overall yet still outperform others in specific tasks such as coding, data analysis, or autonomous agent development. This makes AI selection more like designing a toolkit, where each component serves a unique purpose.

From a market perspective, the absence of a single dominant leader also creates major benefits: it encourages competition, reduces dependence on a single platform, and opens the door to combining multiple models. This serves as the foundation for hybrid AI systems, which are rapidly becoming the new standard in technology-driven enterprises.
2. Benchmarks: The Numbers and Their Real Meaning
Modern benchmarks such as MMLU, GPQA, SWE-bench, MMMU, and ARC-AGI-2 have evolved beyond simply testing knowledge. They are designed to evaluate reasoning ability, multi-step planning, and adaptation to unfamiliar situations.
In SWE-bench (the benchmark that most closely resembles real-world software development environments), Claude Opus 4.6 often leads. High scores here reflect not only coding ability but also a model’s capacity to understand system architecture, dependencies, and business logic. This is a type of capability that is extremely difficult to achieve through learned patterns alone.
By contrast, benchmarks such as GPQA Diamond and ARC-AGI-2 demand advanced reasoning, where Gemini 3.1 Pro frequently demonstrates an advantage. These tests intentionally eliminate opportunities for memorization, forcing models to construct reasoning from first principles and thereby measuring genuine generalization ability.
Meanwhile, GPT-5.4 does not always dominate individual benchmarks, but it consistently delivers high and stable performance across most evaluations. This reflects a clear strategic direction: optimizing versatility and reliability rather than maximizing performance in a handful of isolated metrics.
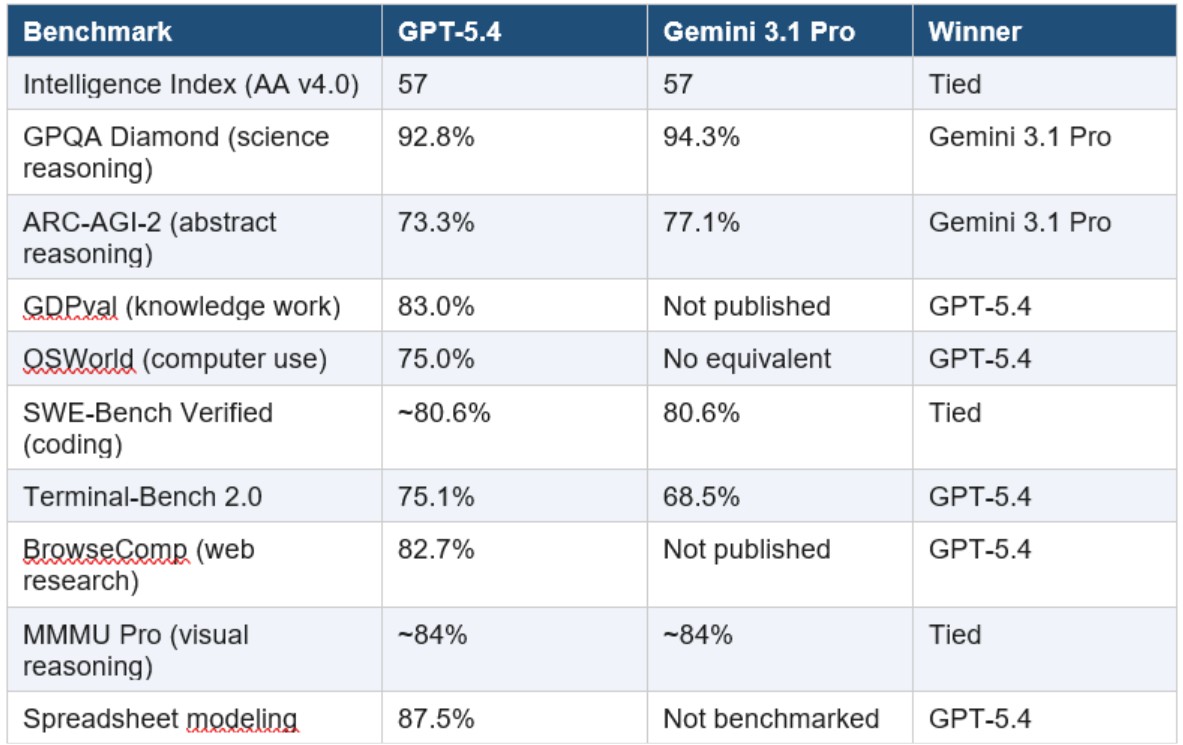
However, benchmarks should be viewed realistically. They do not measure many critical factors such as operational costs, latency, integration capabilities, or long-term workflow performance. Furthermore, some benchmarks may become “over-optimized,” producing impressive scores that do not accurately represent real-world user experiences. Therefore, benchmarks should be treated as an initial guide, while final decisions should be based on testing within actual environments.
3. Claude’s Advantages
In software development, Claude Opus 4.6 stands out because of its deep understanding of systems rather than merely producing syntactically correct code. This distinction becomes increasingly important when moving from simple coding tests to real-world enterprise environments.
Claude can work with large codebases, understand multiple modules, and identify bugs buried deep within complex systems. More importantly, it can propose system-level solutions that ensure bug fixes do not negatively impact other parts of the application. This is especially critical in complex architectures with numerous dependencies.
Claude’s debugging capability is also highly explanatory. Instead of merely providing corrected code, it typically analyzes root causes, explains why an issue occurred, and suggests solutions supported by clear reasoning. This helps developers not only fix problems but also gain deeper insight into their systems.
Additionally, Claude performs exceptionally well in multi-step agent workflows. In modern systems, AI does more than answer questions—it performs sequences of actions such as reading files, modifying code, running tests, and deploying applications. Claude’s ability to maintain context and long-term objectives helps reduce accumulated errors throughout these task chains.
That said, each model retains its own strengths. Gemini 3.1 Pro may outperform in algorithmic challenges or deep reasoning tasks, while GPT-5.4 excels in ecosystem integration and rapid deployment across diverse environments.
Overall, Claude’s advantage in coding extends beyond writing code itself—it lies in understanding how software is built and operated in the real world. This is what makes it a leading choice for complex technical systems and enterprise AI agent applications.
4. Gemini Takes the Lead
In contrast to coding-focused strengths, Gemini 3.1 Pro stands out because of its deep reasoning and generalization capabilities. In benchmarks such as GPQA and ARC-AGI-2, Gemini consistently demonstrates high accuracy and remarkable stability when solving problems that were never encountered during training.
Gemini’s strength is not merely in producing correct answers but in how it constructs reasoning. Its reasoning chains are typically clear, highly logical, and less dependent on familiar patterns. This is especially valuable in scientific research, complex data analysis, and strategic planning, where answers must be explainable and verifiable.
Its ability to generalize allows Gemini to handle novel situations where no reference data exists. This is a key factor in moving closer to the goal of Artificial General Intelligence (AGI), where a model can adapt to diverse problem domains without specialized retraining.
However, these advantages come with certain trade-offs, such as potentially higher computational costs for complex tasks. Nevertheless, in applications that require both accuracy and deep reasoning, Gemini remains a standout choice.
5. The Strength of GPT-5.4
Although GPT-5.4 does not always rank first in individual benchmarks, it remains the most widely adopted choice across many real-world applications. The reason lies in its balance between performance, stability, and ecosystem integration.

GPT-5.4 can effectively handle a wide range of tasks, including content creation, software development, data analysis, customer support, and workflow automation, without requiring extensive fine-tuning. This significantly reduces deployment costs and development time for businesses.
Another major advantage is the ecosystem surrounding OpenAI. From APIs and plugins to support tools and integration platforms, GPT-5.4 can be incorporated into existing workflows with relative ease. This practical advantage is particularly valuable for organizations that require rapid and stable deployment.
6. Long Context and Multimodal Processing
One of the clearest trends in 2026 is the expansion of context windows. Claude Opus 4.6, Gemini 3.1 Pro, and GPT-5.4 all support processing hundreds of thousands to millions of tokens, enabling work with lengthy documents, videos, images, and multimodal data.
However, the difference lies in how each model utilizes context. Claude excels at understanding long documents and extracting accurate information, making it highly effective for large-scale text analysis. Gemini demonstrates strong coherence across extended data sequences, helping reduce context-forgetting issues.
Meanwhile, GPT-5.4 leverages long context through integration with external tools, enabling AI to interact directly with real-world data systems. This expands its application scope beyond content processing into the orchestration of complex workflows.
7. Cost and Deployment Efficiency
When AI is deployed at scale, cost becomes just as important as performance. Gemini 3.1 Pro is often praised for its performance-to-cost ratio, making it an attractive option for startups and budget-conscious applications.
Claude Opus 4.6 generally comes with higher costs, but in return offers exceptional quality for complex tasks, particularly coding and agent workflows. This makes it well suited for organizations that require high accuracy and are willing to invest in premium performance.
GPT-5.4 occupies a middle ground, providing a balance between cost and capability. Thanks to its strong ecosystem, the total real-world deployment cost of GPT-5.4 can often be lower than expected when compared solely on API pricing.
Overall, selecting a model is not just a technical decision but also an economic one. A model that is technically “better” may not necessarily be the optimal choice if its costs do not align with the scale and objectives of the system.
The competition among Claude Opus 4.6, GPT-5.4, and Gemini 3.1 Pro demonstrates that AI has entered a mature phase where no single model dominates absolutely. Instead, diversity and specialization have become defining characteristics, requiring users to clearly understand their needs in order to choose the right tool.
















VIP Products








Best Selling Products
Adobe Premiere Pro Account
99 USD
Upgrade Genuine Office 365
49 USD
Plugin Retouch4me
69 USD
Windows 10 & 11 Pro Key
36 USD
Upgrade Duolingo Super
29 USD
Capcut Pro 1 Year
39 USD
Copyright Adobe Lightroom Account
59 USD
Adobe Photoshop Copyright - Full App
120 USD
Autodesk All App Account Copyright
120 USD
Genuine Cheap Canva Pro
39 USD
Freepik Premium Account
59 USD
Upgrade genuine Capture One account
120 USD
ChatGPT Plus Account (GPT-4)
16 USD
MidJourney Account
29 USD
Genuine Adobe Illustrator account
99 USD